Introducing Instant Voice Cloning to Narration Box

Today, we are super excited to launch Instant Voice Cloning for everyone.
Over the last few weeks, we’ve rebuilt our text-to-speech stack around two new voice–cloning models that turn 5 seconds of reference audio into a lifelike, controllable voice. Starting today, anyone can create these clones directly inside Narration Box Studio.
In this write-up, we will explore how Narration Box Voice Cloning outperforms every other solution on speed, realism, and long-form stability without any compromise on quality.
Why We Care About “Context-Aware” Cloning
Most traditional text-to-speech and voice cloning systems process one sentence at a time in isolation. While this might be sufficient for short snippets, it quickly becomes problematic in longer formats like tutorials, audiobooks, or explainer videos, where the narration needs to feel like one continuous, human performance. Without context, voices sound robotic: sentence endings are abrupt, emphasis feels arbitrary, and pacing can drift, often speeding up or becoming inconsistent over time.
Our new context-aware cloning engine solves this.
Instead of reading each sentence statically, our system tracks and adapts to the broader flow of narration across entire paragraphs and sections. It learns how the speaker naturally transitions from thought to thought, maintains a consistent rhythm, and uses emphasis and pauses to build clarity and emotional continuity. This leads to voices that feel more human, more cohesive, and significantly easier to listen to over long periods.
.png)
What this means in real use:
- A 20-minute product tutorial doesn’t degrade into “text blocks stitched together”. It sounds like a single, confident take.
- Audiobooks retain the pacing and tone that make human performances compelling.
- Explainer videos and help docs sound less like AI and more like your best human trainer.
Quick metric
In a blind listening test, we compared our context-aware system with a traditional sentence-by-sentence baseline. At the 10-minute mark, listeners rated our output as 18% more natural on average. This gap widened with longer durations, highlighting how critical context modeling becomes for long-form voice work.
Under the Hood (High-Level Overview)
At the heart of our voice cloning engine is a smart handshake between who you are and how you’ve been speaking. We fuse three tightly connected components to create speech that doesn’t just sound like you but sounds like you, thinking out loud in real time.
1. Speaker Fingerprinting
We start with a short voice sample, anywhere from 5 to 300 seconds. A compact encoder compresses it into a unique 256-dimensional “voice print” like an acoustic fingerprint. It captures your tone, accent, vocal quirks, and pacing. Think of it as the DNA of your voice: compact, precise, and instantly recognizable.
2. Discourse Tracker
As text is processed, we don’t treat each sentence in isolation. Instead, a lightweight model keeps track of how previous sentences were spoken, things like pacing, emphasis, and intonation patterns. This running context is passed to the synthesizer, helping maintain consistency across paragraphs and avoiding unnatural shifts in tone or speed.
3. Multi-Band Vocoder
Finally, a vocoder generates raw audio by combining the text, the speaker fingerprint, and the discourse context. For most users, this happens in near real-time using a fast, multi-band architecture. For higher fidelity, our Premium tier uses a diffusion-based vocoder that can better capture subtle details, like soft breaths or slight inflections that make the voice sound more lifelike.
Speed & latency
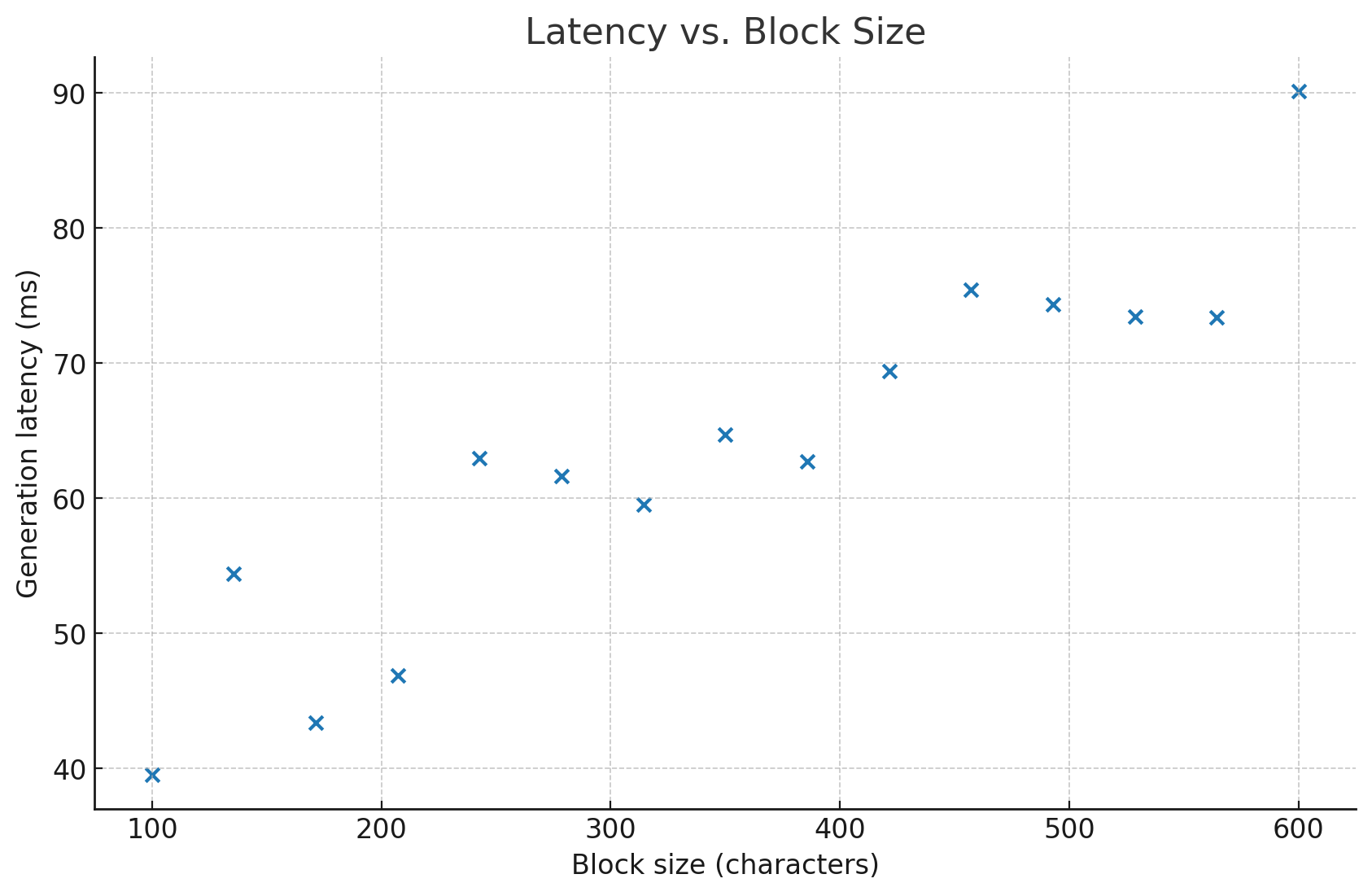
You’ll feel that speed directly in Studio: tweak a sentence, hit Generate, and hear the revision in a heartbeat.
Audio sample lengths (what actually matters)
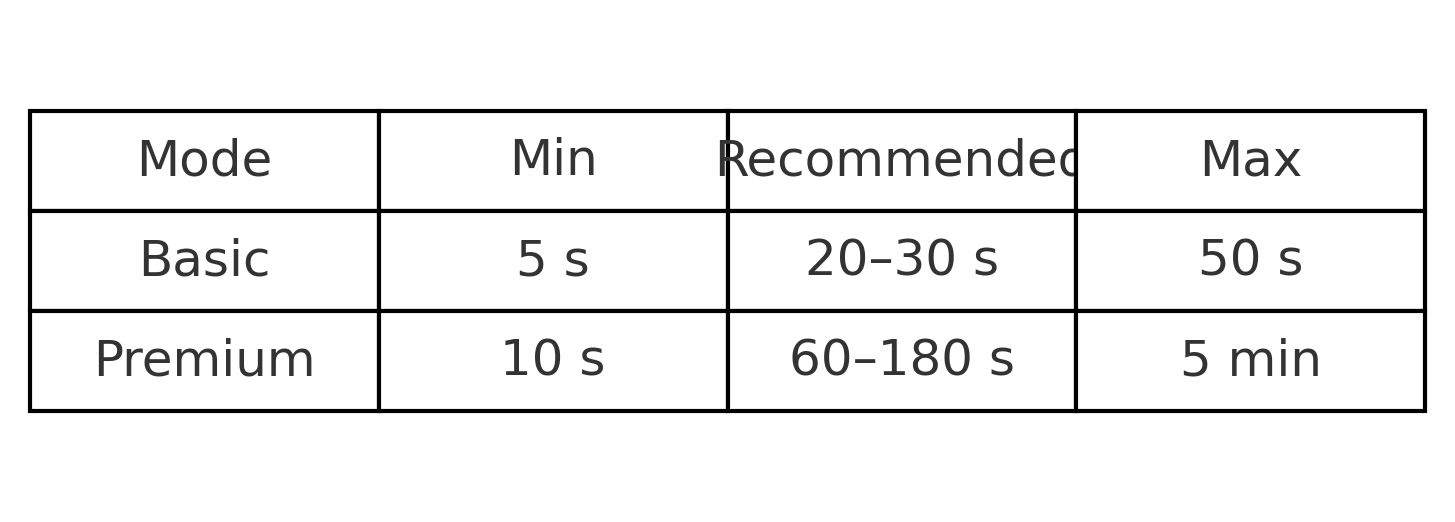
Five to ten seconds is one voice note on your phone, good enough for social media or placeholder reads. For audiobooks or multilingual training, invest the extra minute to hit the recommended range.
Benchmarks that translate to real work
We ran the standard MOS (Mean Opinion Score) tests, where listeners rate the naturalness of voices on a scale of 1 to 5. But we didn’t stop there. We also looked at a more telling metric for creators: “How many edits before you’re comfortable hitting export?”
First-Take Accept Rate
This measures how often the first generated take is good enough to publish without changes.
- Basic voices: 71% of first takes were accepted as-is
- Premium voices: 84% of first takes required no tweaks
In other words, creators are skipping fewer retakes, rewriting less, and getting publish-ready audio faster, especially with Premium.
.png)
YouTube Performance
In early pilot runs with creators, we tested the same video script with two versions: one using a generic narrator, and one using our cloned voices.
Result: The cloned version lifted average watch time by 12%, a clear sign of stronger engagement and retention.
Time Savings in E-Learning
For longer content like training modules, the difference is even more tangible. On average, creators save 8 to 10 hours per 1-hour module time that would otherwise go into voice recording, retakes, syncing, and edits.
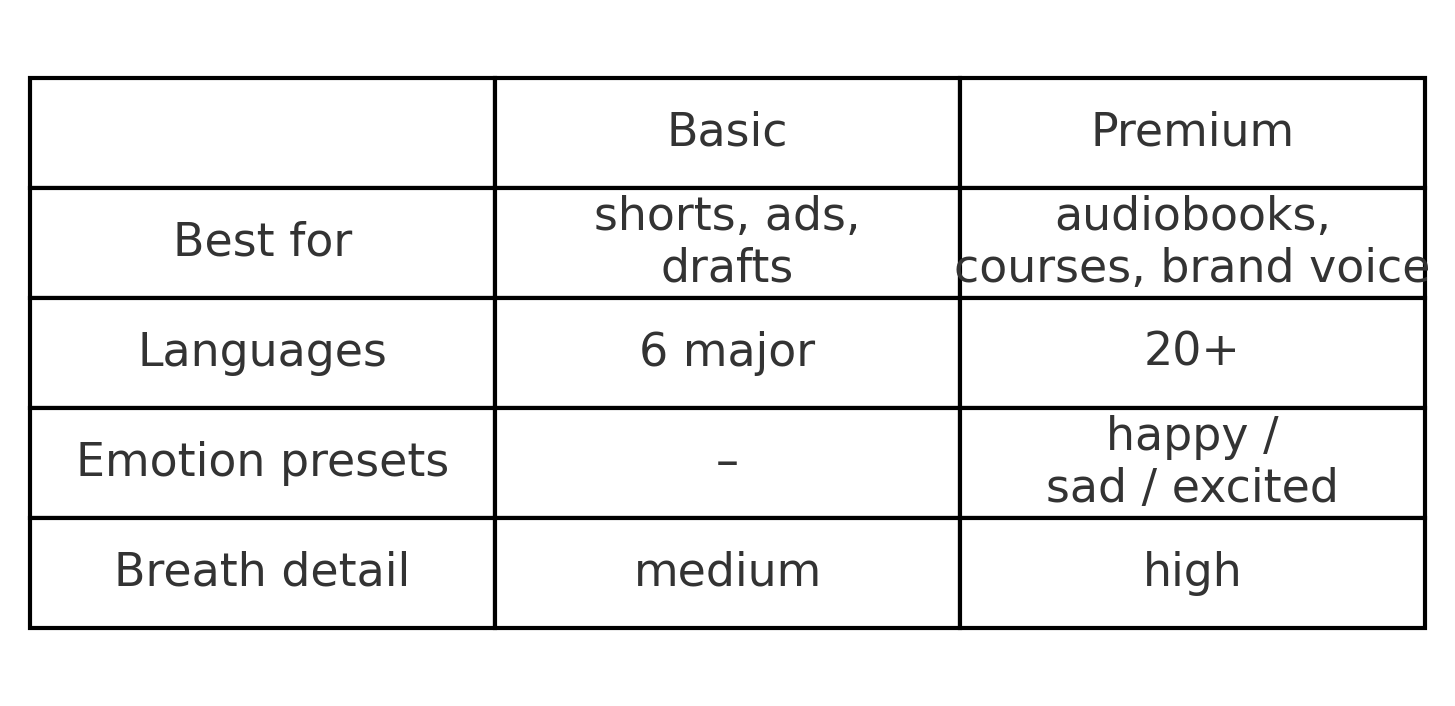
Basic vs. Premium: which one for which job?
.png)
Guardrails & Ethics
Narration Box is committed to responsible AI use and protecting individuals from misuse of voice technology. To ensure this, we enforce a set of ethical, legal, and technical guardrails designed to prevent abuse, promote transparency, and respect individual rights. By using our voice cloning services, you agree to comply with the following terms:
1. Explicit Consent Required
You may only upload or submit voice samples that you own or have obtained explicit, verifiable legal rights to use. Submitting voices without the consent of the speaker (or rights holder) is strictly prohibited and may lead to immediate suspension of your account, legal action, or both. You are solely responsible for securing appropriate permissions from third parties.
2. Tamper-Proof Watermarking
All audio generated through our system contains an inaudible digital watermark that is cryptographically linked to your account. This allows us to trace the source of any misuse and take enforcement action against prohibited behavior. The watermark does not affect audio quality and is not removable or alterable by the end user.
3. Zero Tolerance for Harmful Content
We do not allow the generation of voice content that impersonates real individuals without their consent, or content that promotes hate speech, violence, harassment, misinformation, political manipulation, or any form of targeted harm. Our systems are actively designed to detect and block such content automatically. Repeated attempts to circumvent these filters will result in termination of service.
4. User-Controlled Data Retention
You maintain full control over your uploaded samples and generated voice clones. You may delete them at any time from your dashboard. Once deleted, they are permanently removed from our active systems and are not retained, reused, or recycled for any future training or inference.
5. Legal Responsibility Lies with the User
You are solely responsible for the legal and ethical use of any generated audio content. Narration Box does not monitor or approve individual outputs and cannot be held liable for user-generated misuse. If you are unsure whether a specific use is permitted, consult a qualified legal advisor before proceeding.
Try it now
Voice cloning lives entirely inside Studio—no API, no SDK, nothing to install. Sign in, drop a five-second clip, and you’ll hear your AI twin in under a minute.
Curious about cost? Check the pricing page for plan breakdowns.